相关视频 黑马的zookeeper
基础概念
Zookeeper是Apache Hadoop的子项目,是一个树形目录服务。 Zookeeper是一个分布式的,开源的分布式应用程序协调服务(可用于管理分布式应用程序) zookeeper主要提供的功能
配置管理 1 2 3 4 如多个机器的应用程序配置文件中配置了同一个数据库 若数据库地址变了,就需要每个应用程序都去改配置信息,很麻烦 所以可以设置配置中心,服务连接到配置中心,获取公有配置信息 配置信息变了,在配置中心改即可,服务仍旧可以用,不需要修改
分布式锁 1 2 多个机器访问同一个数据,就需要在多个机器之间有一个锁,就是分布式锁 访问数据之前,机器先获取分布式锁才能继续访问,未获取分布式锁的机器则等待
集群管理 1 2 也就是可以作为注册中心使用,Provider给Registry服务的信息 Consumer需要访问Provider的服务,则从Registry获取服务的信息,再进行RPC访问
安装 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 cd ~/softwarewget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz tar -zxvf zookeeper-3.4.6.tar.gz rm -rf zookeeper-3.4.6.tar.gzcp ~/software/zookeeper-3.4.6/conf/zoo_sample.cfg ~/software/zookeeper-3.4.6/conf/zoo.cfgvi ~/software/zookeeper-3.4.6/conf/zoo.cfg dataDir=/home/easul/software/hadoop-data/zk_data echo " ZOOKEEPER_HOME=/home/easul/software/zookeeper-3.4.6 PATH=\$ZOOKEEPER_HOME/bin:\$PATH export PATH " >> ~/.bash_profilesource ~/.bash_profilezkServer.sh start
zookeeper的bin中脚本解释
1 2 zkCli: zookeeper客户端脚本,可用于改造zookeeper中的数据, zkServer: zookeeper服务端脚本,用于zookeeper的启动,停止等操作
集群管理和配置管理不需要写代码,可用zkCli.sh维护,分布式锁可能需要写代码
命令操作 数据模型
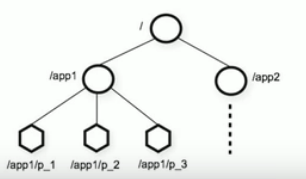
Zookeeper是一个树形目录服务,数据模型和Unix的文件系统目录树类似,有层次化结构
每个结点是ZNode,每个结点都会保存自己的数据和结点信息
结点可以有子结点,允许少量(1MB)数据存储在该结点
结点的四大类
PERSISTENT:持久化结点,zookeeper关了,数据也还在
EPHEMERAL:临时结点,-e,zookeeper关了,数据就没了,只在当前会话有效
PERSISTENT_SEQUENTIAL:持久化顺序结点,-s,创建的结点有编号
EPHEMERAL_SEQUENTIAL:临时顺序结点,-es,创建的结点有编号
服务端常用命令 1 2 3 4 5 6 7 8 zkServer.sh start zkServer.sh status zkServer.sh stop zkServer.sh restart
客户端常用命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 zkCli.sh -server localhost:2181 quit ls /ls /zookeeperls -s /zookeepercreate /app1 create /app1 easul_test create /app1/app11 child_test create -e /app1/app12 child_test2 create -s /app1/app13 child_test3 create -es /app1/app14 child_test4 get /app1 set /app1 new_datadelete /app1 deleteall /app1 help
结点详细信息的解释
1 2 3 4 5 6 7 8 9 10 11 czxid: 结点被创建的事务ID ctime: 创建时间 mzxid: 最后一次被更新的事务ID mtime: 修改时间 pzxid: 子结点列表最后一次被更新的事务ID cversion: 子结点的版本号 dataversion: 数据版本号 aclversion: 权限版本号 ephemeralOwner: 用于临时结点,代表临时结点的事务ID,如果为持久结点,则为0 dataLength: 结点存储的数据的长度 numChildren: 当前结点的子结点个数
JavaAPI操作 Curator常识
是Apache zookeeper的java客户端库
常见zookeeper的Java API
原生Java API(不好用)
ZkClient(原生Java API的简化封装)
Curator(最好用,简化了zookeeper客户端的使用)
由Netfix研发,捐给了Apache,现为Apache顶级项目
官网 可以查看curator相关信息
zookeeper3.5.x和zookeeper3.4.x都用curator4.0以上
Curator常用操作 准备 创建maven的java项目
1 2 mvn archetype:generate -DgroupId=ml.lightly -DartifactId=demo -DarchetypeArtifactId=maven-archetype-quickstart -Dversion=0.0.1-SNAPSHOT -DinteractiveMode=false
pom.xml依赖
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <dependency > <groupId > org.apache.curator</groupId > <artifactId > curator-framework</artifactId > <version > 4.3.0</version > </dependency > <dependency > <groupId > org.apache.curator</groupId > <artifactId > curator-recipes</artifactId > <version > 4.3.0</version > </dependency > <dependency > <groupId > org.slf4j</groupId > <artifactId > slf4j-api</artifactId > <version > 2.0.0-alpha5</version > </dependency > <dependency > <groupId > org.slf4j</groupId > <artifactId > slf4j-log4j12</artifactId > <version > 2.0.0-alpha5</version > <scope > test</scope > </dependency >
日志配置文件log4j.properties,放到resources下
1 2 3 4 5 log4j.rootLogger = off,stdout log4j.appender.stdout = org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target = System.out log4j.appender.stdout.layout = org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern = [%d{yyyy-MM-dd HH/:mm/:ss}]%-5p %c(line/:%L) %x-%m%n
CuratorTest.java,放到test目录
1 2 3 4 5 package ml.lightly.curator;public class CuratorTest {}
建立连接 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 import org.apache.curator.RetryPolicy;import org.apache.curator.framework.CuratorFramework;import org.apache.curator.framework.CuratorFrameworkFactory;import org.apache.curator.retry.ExponentialBackoffRetry;import org.junit.Test;public class CuratorTest { @Test public void testConnect () { RetryPolicy retryPolicy = new ExponentialBackoffRetry (3000 , 10 ); CuratorFramework client = CuratorFrameworkFactory.builder() .connectString("master:2181,salve1:2181,slave2:2181" ) .sessionTimeoutMs(60 * 1000 ) .connectionTimeoutMs(15 * 1000 ) .retryPolicy(retryPolicy) .namespace("lightly" ) .build(); client.start(); } }
创建结点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 import org.apache.curator.RetryPolicy;import org.apache.curator.framework.CuratorFramework;import org.apache.curator.framework.CuratorFrameworkFactory;import org.apache.curator.retry.ExponentialBackoffRetry;import org.apache.zookeeper.CreateMode;import org.junit.After;import org.junit.Before;import org.junit.Test;public class CuratorTest { private CuratorFramework client; @Before public void testConnect () { RetryPolicy retryPolicy = new ExponentialBackoffRetry (3000 , 10 ); client = CuratorFrameworkFactory.builder() .connectString("master:2181,slave1:2181,slave2:2181" ) .sessionTimeoutMs(10 * 1000 ) .connectionTimeoutMs(5 * 1000 ) .retryPolicy(retryPolicy) .namespace("lightly" ) .build(); client.start(); } @Test public void testCreate () throws Exception { String path = client.create().forPath("/xxx" ); System.out.println(path); String path1 = client.create().forPath("/xxx1" , "asdf" .getBytes()); System.out.println(path1); String path2 = client.create().withMode(CreateMode.EPHEMERAL).forPath("/xxx2" , "asdf" .getBytes()); System.out.println(path2); String path3 = client.create().creatingParentContainersIfNeeded().withMode(CreateMode.EPHEMERAL) .forPath("/xxx3" , "asdf" .getBytes()); System.out.println(path3); } @After public void testClose () { if (client != null ) { client.close(); } } }
查询结点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Test public void testGet () throws Exception { byte [] data = client.getData().forPath("/xxx1" ); System.out.println(new String (data)); List<String> children = client.getChildren().forPath("/" ); System.out.println(children); Stat stat = new Stat (); client.getData().storingStatIn(stat).forPath("/xxx1" ); System.out.println(stat); }
修改结点 1 2 3 4 5 6 7 8 9 10 11 12 13 @Test public void testSet () throws Exception { client.setData().forPath("/xxx1" , "asdffda" .getBytes()); Stat stat = new Stat (); client.getData().storingStatIn(stat).forPath("/xxx1" ); int version = stat.getVersion(); client.setData().withVersion(version).forPath("/xxx1" , "new" .getBytes()); }
删除结点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @Test public void testDelete () throws Exception { client.delete().forPath("/xxx" ); client.delete().deletingChildrenIfNeeded().forPath("/" ); client.delete().guaranteed().forPath("/" ); client.delete().guaranteed().inBackground(new BackgroundCallback () { @Override public void processResult (CuratorFramework client, CuratorEvent event) throws Exception { System.out.println("成功" ); System.out.println(event); } }).forPath("/xxx1" ); }
Watch事件监听
zookeeper允许客户端在指定结点注册一些watcher(监听器),服务端监听结点,一些特殊事件触发后,如结点数据更改,服务端就可以通知注册监听器的客户端
zookeeper的配置中心,注册中心和分布式锁都会依赖这个Watcher事件监听
zookeeper的Watcher事件监听可以实现发布,订阅功能。多个订阅者监听某一个结点,结点数据变化后,zookeeper服务端会通知所有订阅者
Curator引入了Cache来实现对zookeeper服务端事件的监听,Cache可以注册事件的监听也可以缓存一些信息。
Curator中zookeeper的三种watcher
NodeCache:只监听某一个特定结点
PathChildrenCache:监控一个结点的子结点,不包括孙子或重孙结点
TreeCache:监听整棵树的所有结点,即该结点与其所有子结点,也包括孙子或重孙结点
CuratorWatcherTest.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 package ml.lightly.curator;import org.apache.curator.RetryPolicy;import org.apache.curator.framework.CuratorFramework;import org.apache.curator.framework.CuratorFrameworkFactory;import org.apache.curator.framework.recipes.cache.NodeCache;import org.apache.curator.framework.recipes.cache.NodeCacheListener;import org.apache.curator.framework.recipes.cache.PathChildrenCache;import org.apache.curator.framework.recipes.cache.PathChildrenCacheEvent;import org.apache.curator.framework.recipes.cache.PathChildrenCacheListener;import org.apache.curator.framework.recipes.cache.TreeCache;import org.apache.curator.framework.recipes.cache.TreeCacheEvent;import org.apache.curator.framework.recipes.cache.TreeCacheListener;import org.apache.curator.retry.ExponentialBackoffRetry;import org.junit.After;import org.junit.Before;import org.junit.Test;public class CuratorWatcherTest { private CuratorFramework client; @Before public void testConnect () { RetryPolicy retryPolicy = new ExponentialBackoffRetry (3000 , 10 ); client = CuratorFrameworkFactory.builder() .connectString("master:2181,slave1:2181,slave2:2181" ) .sessionTimeoutMs(10 * 1000 ) .connectionTimeoutMs(5 * 1000 ) .retryPolicy(retryPolicy) .namespace("lightly" ) .build(); client.start(); } @After public void testClose () { if (client != null ) { client.close(); } } @Test public void testNodeCache () throws Exception { final NodeCache nodeCache = new NodeCache (client, "/xxx1" , false ); nodeCache.getListenable().addListener(new NodeCacheListener () { @Override public void nodeChanged () throws Exception { System.out.println("结点变化后,监听器被通知后的操作" ); byte [] newData = nodeCache.getCurrentData().getData(); System.out.println(new String (newData)); } }); nodeCache.start(true ); while (true ) { } } @Test public void testPathChildrenCache () throws Exception { final PathChildrenCache pathChildrenCache = new PathChildrenCache (client, "/" , true ); pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener () { @Override public void childEvent (CuratorFramework client, PathChildrenCacheEvent event) throws Exception { System.out.println("子结点变化后的操作" ); System.out.println(event); if (event.getType().equals(PathChildrenCacheEvent.Type.CHILD_UPDATED)) { byte [] data = event.getData().getData(); System.out.println(new String (data)); } } }); pathChildrenCache.start(); while (true ) { } } @Test public void testTreeCache () throws Exception { final TreeCache treeCache = new TreeCache (client, "/" ); treeCache.getListenable().addListener(new TreeCacheListener () { @Override public void childEvent (CuratorFramework client, TreeCacheEvent event) throws Exception { System.out.println("自己或子结点变化后的操作" ); System.out.println(event); } }); treeCache.start(); while (true ) { } } }
分布式锁
情形:单机可以用syncronized或Lock,因为在一个JVM,没有问题,但是多机器多个JVM,多线程锁就无法解决该问题了。所以用分布式锁,多个机器用同一个锁,从而解决多机器的多个线程同时访问一个数据的问题。
用途:用于解决跨机器的进程之间数据同步问题
分布式锁的实现
基于缓存
Redis(性能高,但可能不可靠,有了集群后,master结点没有给slave结点同步数据就挂了,就可能多个人会获取锁)
memcached
基于zookeeper(性能高,可靠)
基于数据库实现,性能低
zookeeper分布式锁原理
核心思想:当客户端要获取锁,就创建结点,使用完锁,就删除结点
客户端获取锁,就在某结点(如lock)下创建临时顺序结点(临时结点,会话断了就释放了,不会因为机器挂了很长时间占用资源。顺序可以保证序号小的先获取锁)
然后获取该结点下所有子结点,如果自己创建的结点序号最小,则认为获取到锁。使用完锁,删除刚刚创建的结点
如果发现自己创建的结点序号不是最小,则表示没获取到锁。然后找比自己小一个的结点,注册事件监听器,监听删除事件(3找2,2找1)
如果发现比自己小的结点被删除,客户端的Watcher会收到通知。此时再次判断自己创建的结点是不是所有子结点中最小的。是则获取锁,否则找比自己小一个的结点,注册事件监听器,监听删除事件
分布式锁的实现 Curator的五种锁
InterProcessSemaphoreMutex:分布式排他锁(非可重入锁)
获取了锁,进入了资源。再想进入该资源,需先释放锁,再重新竞争锁
InterProcessMutex:分布式可重入排他锁
获取了锁,进入了资源。再想进入该资源,可以直接进入。比较麻烦,重入几次就需要释放几次
InterProcessReadWriteLock:分布式读写锁
InterProcessMultiLock:将多个锁作为单个实体管理的容器
InterProcessSemaphoreV2:共享信号量
12306的模拟售票。
1 2 3 4 5 6 7 8 9 10 11 12 13 package ml.lightly.curator;public class LockTest { public static void main (String[] args) { Ticket12306 ticket12306 = new Ticket12306 (); Thread t1 = new Thread (ticket12306, "携程" ); Thread t2 = new Thread (ticket12306, "飞猪" ); t1.start(); t2.start(); } }
Ticket12306.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 package ml.lightly.curator;import java.util.concurrent.TimeUnit;import org.apache.curator.RetryPolicy;import org.apache.curator.framework.CuratorFramework;import org.apache.curator.framework.CuratorFrameworkFactory;import org.apache.curator.framework.recipes.locks.InterProcessMutex;import org.apache.curator.retry.ExponentialBackoffRetry;public class Ticket12306 implements Runnable { private int ticketCount = 10 ; private InterProcessMutex lock; public Ticket12306 () { RetryPolicy retryPolicy = new ExponentialBackoffRetry (3000 , 10 ); CuratorFramework client = CuratorFrameworkFactory.builder() .connectString("master:2181,slave1:2181,slave2:2181" ) .sessionTimeoutMs(10 * 1000 ) .connectionTimeoutMs(5 * 1000 ) .retryPolicy(retryPolicy) .namespace("lightly" ) .build(); client.start(); lock = new InterProcessMutex (client, "/lock" ); } @Override public void run () { while (true ) { try { lock.acquire(3 , TimeUnit.SECONDS); if (ticketCount > 0 ) { System.out.println(Thread.currentThread() + "买了一张票" ); Thread.sleep(100 ); System.out.println("剩余" + (--ticketCount) + "张票" ); } else { break ; } } catch (Exception e) { e.printStackTrace(); } finally { try { System.out.println(Thread.currentThread() + ":" + ticketCount); lock.release(); } catch (Exception e) { e.printStackTrace(); } } } } }
zookeeper集群 Leader选举
Serverid:服务器的ID。给服务器的编号越大,选择算法中的权重越大
Zxid:数据ID。值越大,数据越新。在选举算法中数据越新,权重越大
Leader选举中,某台zookeeper获得超过半数选票,该zookeeper就是leader
有1-5五台机器,按顺序启动,1先启动,只有自己,则选自己,不够半数,无法成为leader
2启动,1和2都选2,不够半数无法成为leader
3启动,1,2和3都选3,够半数,leader产生
4,5启动也不再进行leader的重新选举了,3还是leader
集群搭建 真实集群:不同ip是不同的zookeeper
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 mkdir ~/software && cd ~/softwarewget https://download.java.net/openjdk/jdk8u41/ri/openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz tar -zxvf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gz rm -rf openjdk-8u41-b04-linux-x64-14_jan_2020.tar.gzecho " export JAVA_HOME=/home/easul/software/java-se-8u41-ri PATH=\$JAVA_HOME/bin:\$PATH export PATH # 配置jar包路径 export CLASSPATH=.:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar " >> ~/.bash_profilesource ~/.bash_profilecd ~/softwarewget http://archive.apache.org/dist/zookeeper/zookeeper-3.5.6/zookeeper-3.5.6.tar.gz tar -zxvf zookeeper-3.5.6.tar.gz rm -rf zookeeper-3.5.6.tar.gzcp ~/software/zookeeper-3.5.6/conf/zoo_sample.cfg ~/software/zookeeper-3.5.6/conf/zoo.cfgvi ~/software/zookeeper-3.5.6/conf/zoo.cfg dataDir=/home/easul/software/hadoop-data/zk_data server.1=master:2888:3888 server.2=slave1:2888:3888 server.3=slave2:2888:3888 mkdir -p ~/software/hadoop-data/zk_dataecho "1" > ~/software/hadoop-data/zk_data/myidecho " ZOOKEEPER_HOME=/home/easul/software/zookeeper-3.5.6 PATH=\$ZOOKEEPER_HOME/bin:\$PATH export PATH " >> ~/.bash_profilesource ~/.bash_profilescp ~/.bash_profile easul@slave1:~/ scp ~/.bash_profile easul@slave2:~/ scp -r ~/software/zookeeper-* easul@slave1:~/software scp -r ~/software/zookeeper-* easul@slave2:~/software scp -r ~/software/hadoop-data/zk_data easul@slave1:~/software/hadoop-data scp -r ~/software/hadoop-data/zk_data easul@slave2:~/software/hadoop-data echo "2" > ~/software/hadoop-data/zk_data/myidecho "3" > ~/software/hadoop-data/zk_data/myidsource ~/.bash_profilezkServer.sh start jps
故障模拟 集群角色 集群中所有zookeeper数据是一样的,只是角色不一样
Leader
处理事务请求(增删改是事务请求,查询是非事务请求)
是集群内部各个服务器的调度者
Follower
处理客户端非事务请求,转发事务请求给Leader服务器
参与leader的选举投票
Observer
处理客户端非事务请求,转发事务请求给Leader服务器
不参与leader的选举投票,主要用于分担Follower的非事务请求压力
如果client连接到Follower,请求删除结点,Follower就转发请求到Leader。Leader处理后,结点变少,就会给所有其他服务器同步数据,保证数据一致